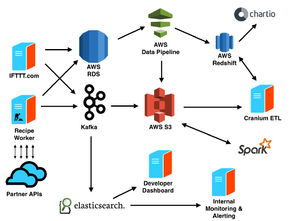
IFTTT (If This Then That) 是一個流行的自動化平臺,每天處理著數十億的事件數據。其背后依賴于一個高度可擴展、可靠的基礎結構和數據處理服務,能夠實時響應用戶的觸發器和動作。以下將深入解析其基礎架構和數據處理服務的核心組成部分及運行機制。
一、基礎架構設計
- 微服務架構:IFTTT 采用分布式微服務架構,將核心功能拆分為獨立的服務,如觸發器服務、動作服務、用戶管理服務等。這種設計提高了系統的模塊化水平,便于獨立擴展和維護。服務之間通過輕量級通信協議(如 gRPC 或 HTTP)交互,確保低延遲和高吞吐量。
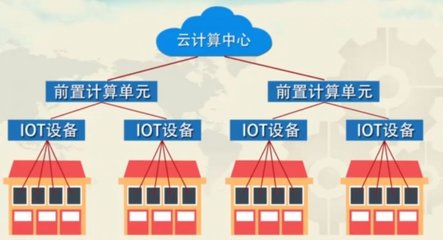
- 事件驅動模型:系統基于事件驅動模式運行。當用戶定義的觸發器(如收到新郵件)被激活時,IFTTT 會生成一個事件。該事件被發布到消息隊列(如 Apache Kafka 或 AWS Kinesis)中,作為數據流的源頭。這種模型支持異步處理,避免了阻塞,提升了系統的響應速度。
- 云原生和容器化:IFTTT 部署在云平臺(如 AWS 或 Google Cloud)上,利用容器化技術(如 Docker 和 Kubernetes)實現彈性伸縮。通過自動擴縮容機制,系統能夠根據事件負載動態調整資源,處理高峰期數十億的事件,同時優化成本。
- 數據庫與存儲:為了處理大規模數據,IFTTT 使用混合存儲方案。關系型數據庫(如 PostgreSQL)管理用戶配置和元數據,而 NoSQL 數據庫(如 Cassandra 或 DynamoDB)存儲事件日志和臨時數據。對象存儲(如 Amazon S3)用于歸檔歷史數據,確保數據持久性和可追溯性。
- 全球負載均衡與 CDN:通過全球負載均衡器(如 AWS ELB)和內容分發網絡(CDN),IFTTT 將請求路由到最近的服務器,減少延遲,提高用戶體驗。這尤其重要,因為用戶分布在全球各地。
二、數據處理服務
- 事件攝入與驗證:當事件觸發時,數據處理服務首先進行攝入和驗證。前端 API 接收事件數據后,使用驗證服務檢查數據的完整性和合法性(例如,驗證 API 密鑰和觸發器參數)。無效事件被過濾掉,以減少后續處理負擔。
- 實時流處理:核心數據處理依賴流處理引擎(如 Apache Flink 或 Apache Storm)。事件從消息隊列流入后,流處理服務實時解析、轉換和路由數據。例如,如果一個觸發器是“天氣變化”,系統會實時獲取天氣 API 數據,并與用戶規則匹配。這個過程需在毫秒級完成,以支持近實時自動化。
- 規則引擎與匹配:IFTTT 的規則引擎是數據處理的關鍵。它存儲用戶定義的“applets”(自動化規則),并根據事件類型進行匹配。引擎使用高效的索引和緩存機制(如 Redis)快速查找相關規則,確保在事件到達時立即觸發對應的動作。
- 動作執行與重試機制:匹配成功后,系統調用外部服務的 API 執行動作(如發送推文或控制智能設備)。為了處理網絡故障或服務不可用,IFTTT 實現了重試機制和死信隊列。如果動作失敗,事件會被暫存并重試多次,直到成功或標記為終止。
- 監控與可觀測性:數據處理服務集成了全面的監控工具(如 Prometheus 和 Grafana),實時跟蹤事件吞吐量、延遲和錯誤率。日志和指標數據被聚合分析,幫助團隊快速診斷問題。A/B 測試和數據分析服務用于優化規則和提升平臺性能。
- 數據安全與合規:IFTTT 采用加密傳輸(TLS)和存儲,確保用戶數據安全。數據處理遵循 GDPR 等法規,通過數據匿名化和訪問控制保護隱私。
三、挑戰與優化
處理數十億事件帶來挑戰,如數據一致性、系統容錯和成本控制。IFTTT 通過以下方式優化:
- 使用最終一致性模型,平衡性能與數據準確度。
- 實施故障轉移和備份策略,確保高可用性(99.9% 以上)。
- 優化數據處理算法,減少冗余計算,例如通過批處理非關鍵事件。
IFTTT 的基礎結構結合了微服務、事件驅動和云技術,而數據處理服務則依賴流處理、規則引擎和健壯的監控。這些元素協同工作,使其能夠高效、可靠地處理海量事件,為用戶提供無縫的自動化體驗。隨著物聯網和 AI 的發展,IFTTT 持續演進其架構,以應對未來數據量的增長。