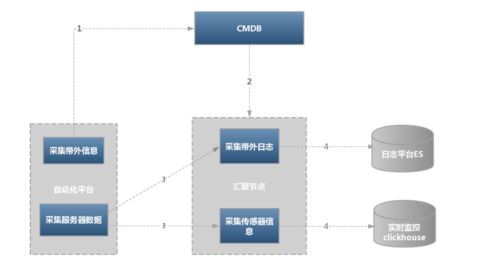
在現代IT環境中,基礎設施硬件的穩定運行是保障業務連續性的基石。隨著數據中心規模的擴大和邊緣計算的普及,硬件監控從傳統的本地化告警逐步演變為智能化、集中化的管理體系。本文將深入探討基礎設施硬件監控的最新趨勢與實踐,并著重分析數據處理服務在監控體系中的核心作用。
一、硬件監控的演進與挑戰
硬件監控已從早期的簡單狀態檢測(如CPU溫度、磁盤使用率)發展到多維度的性能與健康度評估。現代監控系統需要覆蓋服務器、網絡設備、存儲陣列等各類硬件,并實時采集數以萬計的指標數據。海量數據的涌入帶來了三大挑戰:
- 數據采集的實時性與準確性要求極高,任何延遲或遺漏都可能導致故障被忽視;
- 監控數據格式多樣,包括時序數據、日志事件、配置快照等,統一處理難度大;
- 傳統閾值告警易產生噪音,需要智能分析以識別真正有風險的異常模式。
二、數據處理服務:監控體系的智能引擎
數據處理服務作為硬件監控的后端支撐,承擔著數據清洗、聚合、分析與可視化的重任。其核心能力包括:
- 數據采集與標準化:通過Agent、SNMP、IPMI等協議收集原始數據,并轉換為統一的時序數據格式(如Prometheus指標、InfluxDB記錄)。
- 流式處理與實時分析:利用Apache Kafka、Flink等流處理框架,對監控數據進行實時過濾、聚合與異常檢測,及時發現硬件性能拐點。
- 機器學習驅動的預測性維護:通過歷史數據訓練模型,預測硬件故障(如硬盤壽命、風扇失效),實現從“被動響應”到“主動預防”的轉變。
- 數據可視化與告警路由:將處理后的數據通過Grafana、Kibana等工具可視化,并結合智能告警規則(如動態基線、關聯分析)推送給運維團隊。
三、實踐案例:某金融企業硬件監控平臺升級
某大型金融機構在升級其硬件監控體系時,引入了基于云原生架構的數據處理服務:
- 采用Telegraf+Prometheus實現全網硬件指標的秒級采集;
- 通過自研的流處理引擎對CPU、內存、磁盤IO等關鍵指標進行實時聚合,并應用孤立森林算法檢測異常;
- 建立硬件健康度評分模型,結合歷史維修記錄預測服務器故障概率,提前安排硬件更換;
- 最終將監控數據統一接入運維大數據平臺,實現全棧可觀測性。
實踐結果表明,該平臺將硬件故障的平均發現時間從小時級縮短至分鐘級,誤告警率下降60%,年度硬件維護成本降低約25%。
四、未來展望
隨著5G、物聯網和AI技術的深度融合,硬件監控將向“端-邊-云”協同的方向發展。數據處理服務需要進一步強化邊緣計算能力,支持輕量級本地分析與云端協同決策。同時,結合數字孿生技術,構建硬件設備的虛擬映射,實現更精準的狀態模擬與故障推演。
結語
基礎設施硬件監控不僅是技術問題,更是組織運維能力的體現。高效的數據處理服務如同監控體系的“大腦”,通過實時、智能的數據加工,將原始指標轉化為可行動的洞察。未來,隨著算法與硬件的共同進化,我們有望構建出更自治、更可靠的硬件監控生態系統。