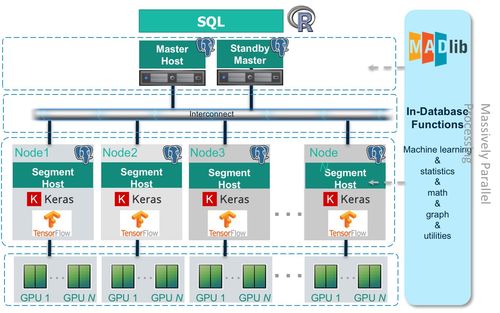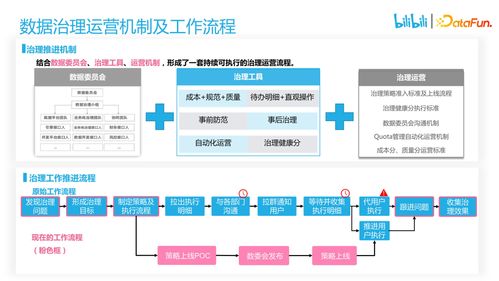
隨著互聯網數據的爆炸式增長,高效的數據處理服務成為企業(yè)數據平臺建設的核心。B站大數據開發(fā)治理平臺作為支撐業(yè)務數據化的關鍵基礎設施,在數據處理服務的設計環(huán)節(jié)積累了豐富的實踐經驗。本文將重點探討該平臺在數據處理服務設計中的核心思路與心得。
一、數據處理服務的定位
B站大數據開發(fā)治理平臺的數據處理服務旨在為內部用戶提供一站式數據處理能力,覆蓋從數據采集、清洗、加工到應用的全鏈路流程。其設計核心在于平衡性能與易用性,既要滿足大規(guī)模數據的高效處理需求,又要降低使用門檻,支持業(yè)務團隊快速實現數據價值。
二、設計原則與技術選型
- 高可擴展性:采用分布式架構,支持水平擴展,適應B站日益增長的數據量。通過資源動態(tài)調度和容器化部署,確保處理任務在高峰期仍能穩(wěn)定運行。
- 統(tǒng)一接口與標準化:提供標準化的數據接入與輸出接口,支持多種數據源(如日志、數據庫、消息隊列)和格式(JSON、Parquet等),減少用戶對接成本。
- 任務調度與管理:集成工作流引擎(如Airflow),支持可視化編排和依賴管理,實現數據處理任務的自動化與監(jiān)控。
三、用戶體驗優(yōu)化
- 低代碼開發(fā):針對非技術用戶,提供圖形化配置界面,簡化ETL流程設計,減少代碼編寫需求。
- 實時與批量處理融合:支持流批一體處理,用戶可根據業(yè)務場景靈活選擇實時或離線計算模式,提升數據處理的時效性。
- 錯誤處理與數據質量監(jiān)控:內置數據校驗、血緣追蹤和告警機制,幫助用戶快速定位問題,保障數據產出的準確性與可靠性。
四、挑戰(zhàn)與應對
在平臺演進過程中,面臨的主要挑戰(zhàn)包括數據孤島整合、計算資源競爭以及多租戶隔離。通過構建統(tǒng)一元數據中心、實施資源配額管理以及優(yōu)化任務調度策略,平臺逐步解決了這些問題,提升了整體服務穩(wěn)定性。
五、未來展望
未來,B站大數據開發(fā)治理平臺的數據處理服務將持續(xù)探索智能化的方向,例如通過AI輔助優(yōu)化任務參數、自動識別數據異常,進一步降低運維成本并提升處理效率。同時,平臺將強化與業(yè)務場景的深度融合,為B站的創(chuàng)新業(yè)務提供更敏捷的數據支撐。
數據處理服務作為大數據平臺的核心組件,其設計需兼顧技術先進性與用戶友好性。B站的實踐表明,以用戶為中心、持續(xù)迭代優(yōu)化的設計理念,是構建高效可靠數據處理服務的關鍵所在。